
_lognostics maps
Studies in Second Language Acquisition
1980-2010
data source: Studies in Second Language Acquisition 1980-2010: data analysis: March 2014
data: 59 papers, 128 nodes, 1058 co-citations, 3+4 clusters
threshold for inclusion: Authors must be cited in at least four different papers; co-citations must appear at least three times.
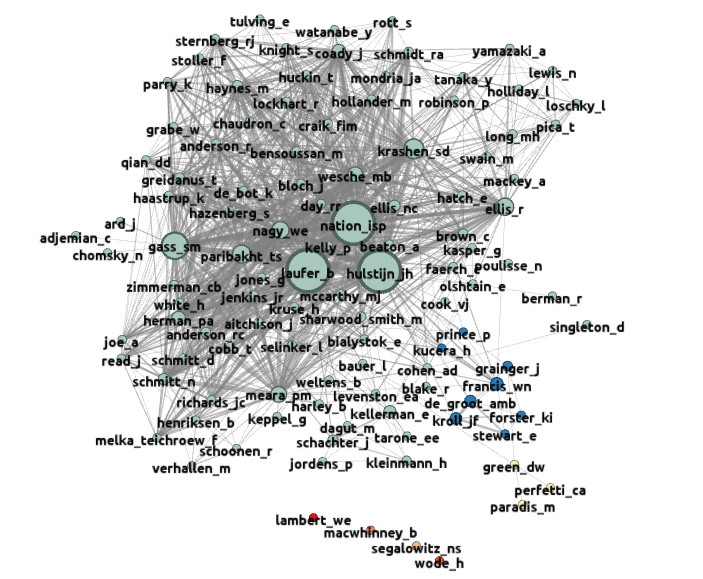
This map shows displays the vocabulary related papers published in Studies in Second Language Acquisition between 1980 and 2010.
128 authors are cited in at least four papers in this data set. Their work falls into three main clusters, with an additional four unconnected singletons.
Cluster I, the very small cluster at the bottom right of the map contains only three members, Green, Perfetti and Paradis. The members of this cluster are all concerned with the psycholinguistics of bilingualism.
Cluster II containing eight members is also a psycholinguistics cluster, but in this cluster the emphasis is on experimental methods that involve word recognition by bilinguals, particularly Dutch-English bilinguals.
Cluster III is a massive cluster consisting of 97 members. This cluster is densely internally connected. However it has no direct links at all with Cluster I, and the few links it shares with Cluster II are mediated through a small number of nodes, notably Hulstijn.
The nodes in the map are sized according to each author's betweenness centrality. This is a measure which tends to favour people who are frequently co-cited with people outside their own cluster. This is not really an issue in this map, as almsot all the sources are fall into a single cluster, and all the central sources lie within this cluster.
Large, dense clusters of this sort are usually produced when a small number of sources are cited in almost every paper. In this case, seven sources: Hulstijn, Nation, Laufer, Paribakht, Wesche, Nagy and Gass form a block of sources who are connected with nearly all the other sources. They therefore provide the orthodox core for this map, but don't help to differentiate smaller groups within the main cluster. If we filter out these seven sources along with their links to other sources, and then filter out the resulting singletons, then we are left with a map which shows that there is much more diversity in the core than is apparent at first sight.
This "donut" map with the hard core removed falls into five clusters.
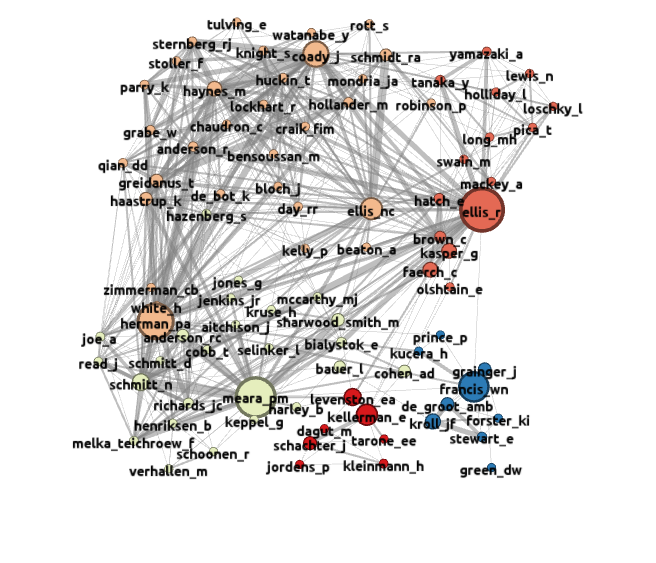
Cluster I at the bottom right of the map contains nine sources, and represents the psycholinguistic research strand identified in the larger map.
Cluster II, focussed on R Ellis, contains few people who would identify thermsleves as vocabulary specialists. Rather, this cluster seems to reflect the broad SLA concerns that characterised Applied Linguistics in the period around 2000.
Cluster III has seven members: Kellerman, Levenston, Dagut, Schachter, Tarone, Jordens and Kleinemann. This cluster has some links with Cluster II and cluster IV, but it is difficult to see what specific features bind this group together. My guess is that the main link here is a set of papers that Kellerman produced dealing with transfer of idioms.
Cluster IV, consisting of 25 sources, is focussed on Meara. This cluster is predominantly made up of European researchers, and biassed towards vocabulary testing and assessment.
Cluster V, the remnant of the large cluster in the previous map contains the remaining 32 sources. This cluster seems to be predominantly, but not exclusively, North American, It has a strong emphasis on vocabulary acquisition through reading, with lexical inferencing appearing as a significant sub-theme.
Again, the nodes in this map are sized by their "betweenness centrality". The Central Figures in this new map are R Ellis, Herman, Meara, Francis and Coady, who each act as foci for a cluster and have significant links with other clusters as well.
Points to note
The central figures in the main map are: Hulstijn, Gass, Nation, Laufer, Krashen, Cohen, Green, R Ellis, Paribakht and Nagy.
Gass's importance may be boosted by the fact that she was editor of SSLA during most of the period being analysed. Green's position is probably due to his being the only link between two of the clusters in the main map.
Interestingly, Hulstijn, does NOT define himself as a vocabulary researcher, despite his pre-eminent position as a Central Figure in this data set.
It is also worth noting that the corpus linguistics and the formulaic sequence research identified in the Applied Linguistics map is almost entirely missing here. Also missing is research on vocabulary testing and research on CALL, all of which may be appearing in their own journals.