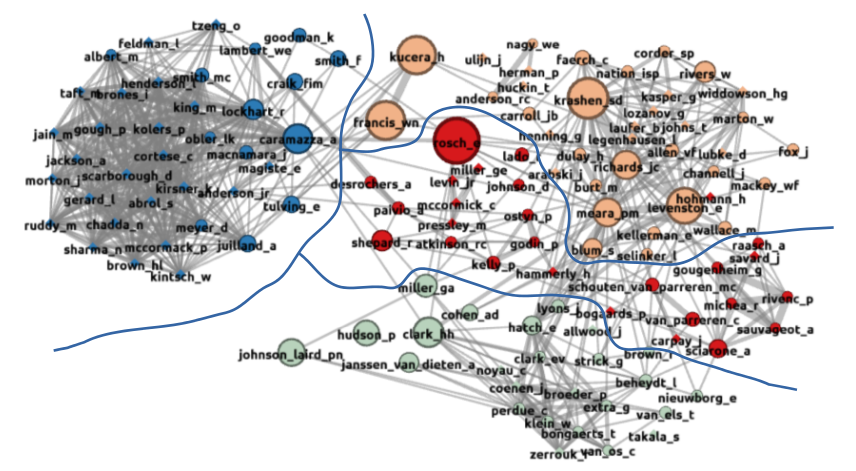
This map shows the co-citation patterns between authors who are cited in the 1986 research listed in the VARGA database.
data source: VARGA 1986: data analysis: January 2018 data: 81 papers, 125 sources, 2031 co-citations, 4 clusters of influence threshold for inclusion: Authors must be cited in at least three different papers.
Sources are sized according to their betweenness centrality.
125 sources are cited in at least three of the papers in the 1986 data. This number is somewhat larger than the conventional figure of 100 sources usually used for co-citation analysis. This inclusion threshold is the same as the threshold we used for the analysis of the 1984 and 1985 data.
The main point to note in this map is that the number of papers published in 1986 is about 10% lower than the number of papers published in 1985 (1985: 92 papers, 1986: 81 papers). However, the number of sources that meet our inclusion threshold is almost 50% larger, and the number of co-citations to be mapped has almost doubled.
The map identifies four main clusters in the 1986 data. This map is much more coherent than the earlier maps in this series, and it is relatively easy to identify clusters that are open to a straightforward interpretation (see below). The pyscholinguistics cluster which dominated the earlier maps, but was much reduced in 1985, has returned to its former strength, but with a somewhat different cast of players. plays a much reduced role in the 1985 data. The applied linguistics sources have coalesced into three clusters that are strongly interconnected with each other. The small detached clusters that we identified in 1985 are no longer a feature in the 1986 map.
Cluster I, at the Western edge of the graph is the by now familiar psycholinguistics group of influences. As usual, the members of this cluster are very frequently cited alongside each other, but they have very limited co-citations with members of the other clusters. Most of these between cluster co-citations link to Kucera and Francis, the standard word frequency count that
both psychologists and applied linguists were using at this time. The density of co-cocitation links within this cluster is striking. Cluster II, at the bottom of the map is slightly more difficult to characterise. This cluster too contains some influences who are psycholinguists (notably Johnson-Laird and George Miller), and it also contains a group of influences who are mainly concerned with L1 acquisition
(Eve Clark, Herbert Clark and Roger Brown). The main feature of this cluster is the relatively dense part of the map which includes Broeder, Extra, Bongaerts, van Els, Zerrouk, Perdue and Klein. These influences are all members of a large international project team funded by the European Science Foundation, and hosted by the Max Planck Institute in Nijmegen. This
project was a very large scale comparative study of the way migrants acquire typologically different languages in naturalistic settings. The project used an interesting methodology which relied heavily on in depth observations of a small number of Subjects across a large number of language pairs – five target languages and six source languages in total. Klein was the overall
director of the project. Broeder, Extra and van Hout were part of the Dutch team which looked at acquisition of Dutch by L1 Arabic speakers and by L1 Turkish speakers. Giacobbe and Camarotta, who were identified earlier as authors of multiple papers in the 1986 data set, were part of the French team working on this project, which looked at acquisition of French by L1
Spanish speakers and L1 Arabic speakers. Both teams had a special interest in the lexical development demonstrated by their Subjects, but unlike the reports of the Dutch team, Giacobbe and Camarotta’s reports did not appear early enough to influence the other work in the 1986 data set. Cluster IIIat the North East section of the map, is easily recognisable as a cluster that deals with mainstream L2 vocabulary research. Interestingly, this cluster is much more tightly interconnected in this map than it was in our earlier maps, and this suggests that there is a growing consensus among L2 vocabulary researchers over who the main influences are. It is also worth noting that most of the sources co-cited in this cluster are themselves L2 vocabulary researchers, and a very high proportion of them appeared as significant influences in our 1985 map. Perhaps these are the early signs of a self-reflexive orthodoxy emerging in the field? Cluster IV, in the centre of the map, is the most difficult cluster to characterise. Two main sub-groups stand out among these influences. At the left of this cluster is a group of researchers whose main interests focus on imagery and the role of imagery in memory. Particularly striking here is a group of psychologists who had earlier published a lot of research into the use of mnemonics in vocabulary acquisition (Levin, McCormick, Pressley and Atkinson, whose main work appeared in the late 1970s). The other end of this cluster comprises the Français fondamental group (Gougenheim, Michea, Rivenc, Sauvageot and Savard), and three Dutch researchers (van Parreren, Schouten-van Parreren and Sciarone) who are mainly interested in the way learners can infer the meanings of words from context. The single idea that seems to link these separate groups appears to be the specific conditions under which learning words can take place. In this respect, cluster IV looks to be concerned with small-scale vocabulary learning, whereas cluster III might be more concerned with large scale vocabulary learning, with a particular interest in vocabulary use.
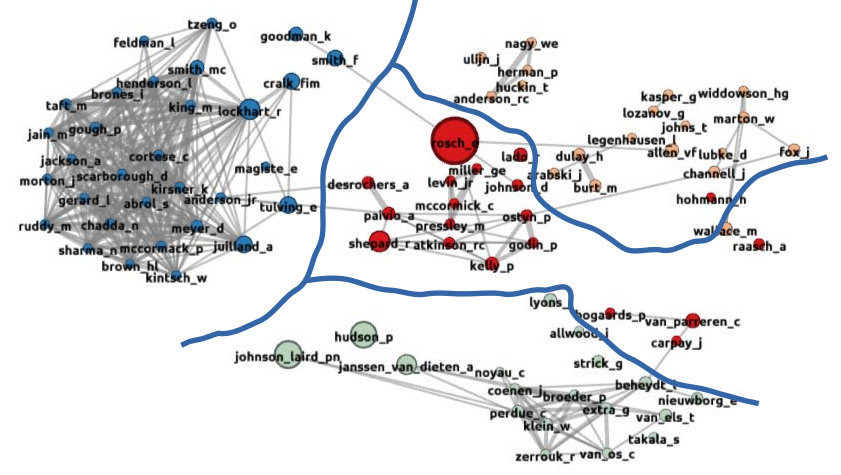
As in earlier maps, the majority of the influences in the 1986 map are new sources who did not appear in the research outputs of previous years. The co-citation analysis identifies four clusters of influences in this data, and these are shown in the figure below.
new entries in the 1986 data set
This analysis broadly mirrors the structure that we saw in the full 1986 data. The main difference from 1985 is the very large number of new sources in Cluster I. These 31 new sources make up just over a quarter of the sources who appear in the overall 1986 map. The new theme in 1986 seems specifically to be word recognition in an L2, a theme which has not been strongly represented in the earlier maps. Several of the papers included in the 1986 data set come from a single volume of papers edited by Vaid, and this may have influenced the emergence of a new and unusually coherent theme in the 1986 map.
The cluster of new entrants at the Southern edge of the map is largely made up of the members of the ESF project described earlier. It also contains a couple of influences in the area of semantics: Lyons and Beheydt were not
significant sources in the 1985 map, but did play a role in earlier maps, suggesting that they are returners here, rather than genuinely new sources. This cluster, despite its strong internal structure, is largely isolated from the rest of the map: it has no co-citation links with two of the other
clusters, and only a weak geographical link with the remaining cluster.
The cluster of new entrants at the Northeast sector of the map contains two sub-clusters. The Nagy-Huckin-Anderson-Herman-Ulijn sub-cluster represents a set of influences who are mainly concerned with L2 reading skills. (We might have expected them to be closely linked with Goodman and Smith in the psycholinguistics cluster – both eminent figures in L1 reading studies.) The remaining members of this cluster seem to represent a set of eclectic approaches towards vocabulary acquisition. Lozanov (of Suggestopedia fame) is a notable figure in this group; Johns and Fox represent the beginnings of a computer-based approach to vocabulary acquisition; Dulay and Burt reflect the increasing dominance of Krashen in the US research; Allen and Wallace both authored text books on vocabulary teaching.
The cluster at the centre of this map, is also difficult to characterise succinctly. Rosch has appeared as a significant influence in our earlier maps, but in spite of her central role in the overall graph, she seems to be somewhat disconnected from the other influences in this cluster. Two sub-groups can be identified. The van-Parreren-Carpay-Bogaards subgroup is a
nucleus of Dutch vocabulary researchers. The remaining members of this cluster are very specifically interested in imagery and mnemonics as they apply to L2 vocabulary acquisition.
For a more detailed discussion of this map see: Meara, PM
Laying the Foundations: A bibliometric analysis of L2 vocabulary research in 1982-86.
Linguistics Beyond and Within 4(2018), 108-128.