 |
||
Lognostics Maps: Computer Assisted Language Learning 1980-2010 |
||
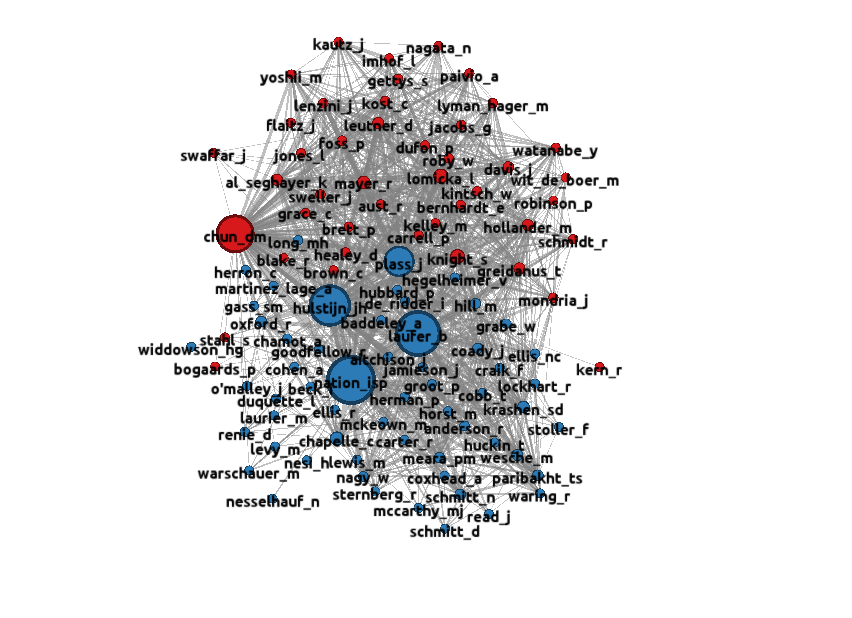
data source: A set of studies published in four specialist journals between 1990-2010: data analysis: April 2014
This map shows displays the vocabulary related papers published in Computer Assisted Language Learing, CALICO Journal, ReCALL and Language Learning and Technology between 1990 and 2010. Cluster I, the cluster at the bottom of the map, seems to consist mainly of people who we might expect to appear in a more general map of vocabulary research about this time. Cluster II, the cluster at the top of the map, seems to identify researchers who are more specifically concerned with L2 vocabulary acquisition using CALL approaches. The two clusters are very densely interconnected, and really form a single large cluster. Large, dense clusters of this sort are usually produced when a small number of sources are cited in almost every paper. In this map, five sources play a dominant role: Nation, Laufer and Hulstijn will be familiar to readers from other maps in this series. Chun and Plass co-authored an important paper on glossing which is very widely cited within the CALL literature. Because these five sources are co-cited with almost every other source in the map, they mask some vartiation within the two main clusters. This variation can be seen in the "donut" map below.
In this map, the five central figures - all co-cited with at least 80 other sources - have been filtered out, and a small number of singletons resulting from this operation have also been removed. The remaining nodes have been regrouped into 4 clusters, with the sources sized according to their betweenness centrality. This measure gives added importance to sources who are co-cited across many clusters. Cluster I is the large cluster at the top of the map, dominated by Knight, Lomicka, Al-Seghayer and Mayer. This custer seems to be the principle group of CALL specialists. Cluster II, at the bottom right of the map, is a group of L2 vocabulary specialists, notably, Meara, Paribakht, Wesche and Krashen. Cluster III, at the left of the map, is dominated by Oxford. This cluster seems to have a special interest in vocabulary learning strategies. Cluster IV, the small central cluster containing Chapelle, Goodfellow, Warschauer, Levy, Coady, Groot and Hill may represent a sort of theoretical grouping, slightly critical of the mainstream work on vocabulary, and leaning towards vocabulary testing.
Points to note What is really surprising here is that the main sources in CALL vocabulary work are much more closely linked with the general CALL group than they are with the vocabulary research cluster. Knight represents research on dictionaries; Lomicka and Alseghayer are part of a significant glossing group. Apart from these sources, there does not appear to be a distinctive CALL vocabulary strand emerging within this data, unless it is to be found in the small cluster dominated by Chapelle. This cluster looks oddly placed, however, and slightly detached from the main sources both in CALL and in Vocabulary Research. Oxford's role in this map deserves further analysis. Oxford emerges as a significant figure because she has consistent co-citation links with all the other main clusters. Surprisingly, however, her work is not consistently co-cited alongside the work of the main vocabulary theory cluster.
|

(c) 2014 Paul Meara