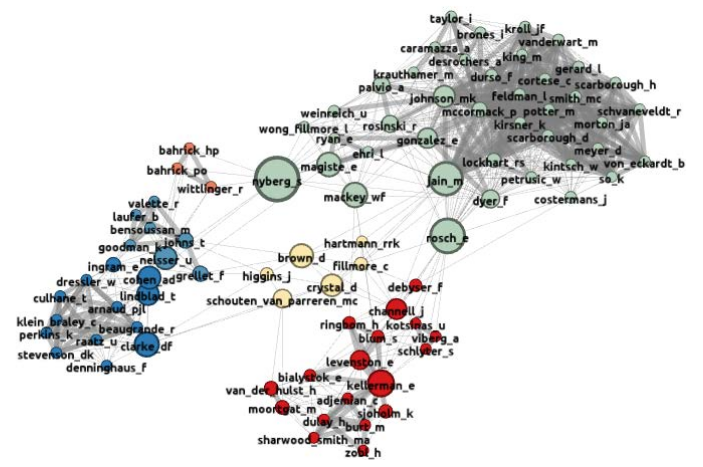
This map shows the co-citation patterns between authors who are cited in the 1984 research identified in the VARGA database.
data source: VARGA 1984: data analysis:January 2017 data: 33 papers, 95 nodes, 232 co-citations, 6 clusters of influence threshold for inclusion: Authors must be cited in at least three different papers. Co-citations occurring less than twice are excluded.
Nodes are sized according to their betweenness centrality.
95 authors are cited in at least two of the papers in the 1984 data. This number is close to the conventional figure of 100 authors usually used for co-citation analysis. However, in order to reach these numbers, the threshold criterion has to set at a very low level, so this map should be treated with appropriate caution.
The main point to note in this map is that the number of papers published in 1984 is low compared with the 1983 output. This is partly due to the fact that no thematic journal issues or relevant books were published in this year.
The map identifies six clusters in the 1984 data. As in 1983, the 1984 map is clearly divided into two sectors with very different characteristics.
Cluster I at the Northeastern corner of the map is the largest cluster. It consists mainly of psychologists whose work has influenced the study of the way bilingual subjects perform on
verbal tasks. This cluster will be familiar to readers from our analyses of data from earlier
years, and it contains a number of influences that were identified in these earlier analyses.
This persistent cluster has a high level of connectivity within itself, but it has no strong links
to the other clusters in the map. Cluster II, in the South Central portion of the map, also includes a number of sources who
were identified in our analysis of the 1983 data. The sources in this cluster are mainly
concerned with lexical errors and lexical transfer, and seem to be strongly associated with the
Interlanguage Studies Bulletin group based in Utrecht. The cluster also includes two detached sub-clusters (Albert and Obler, Moortgat and van der Hulst) and West who appears here as a detached singleton. In our analysis of the 1983 data, Albert and Obler's work was more closely associated with the formal psycholinguistic studies. This subtle shift may suggest that Albert and Obler's work was beginning to influence linguists, and seems to be a sign that mainstream vocabulary research was becoming slightly more aware of the psycholinguistic issues that were considered important at the time. The Moortgat and van der Hulst sub-cluster seems to be a reflection of the growing importance of lexical factors in mainstream linguistic analysis. Cluster III at the Southwestern edge of the map is the least coherent of the groups
identified in this analysis. Here it appears as three small subclusters, two pairings and a set of
seven detached singletons. The sub-cluster containing Bahrick, Bahrick and Wittlinger represents a small literature that deals with long term acquisition and retention of vocabulary, the first time that this topic has appeared in these maps. The Dressler/Stevenson subcluster is mainly concerned with the practical consequences of a small vocabulary. Clarke and Nation is a paper that deals with guessing the meanings of unknown words. Cohen and Oller seem to be the principal US authors working on vocabulary at this time. The most notable feature in this cluster is the emergence of Paul Nation as the key figure in terms of betweenness centrality. The betweenness centrality measure reflects how likely it is that a source will appear on a path connecting two randomly selected sources in the map. This means that sources with a high betweenness centrality score tend to be people who share co-citation links with two or more large clusters. In this case, the critical co-citations are Nation ~ Kucera and Nation ~ Francis, which show up as weak links in Figure 1, where they provide the only direct links between Cluster I and Cluster III. Kucera and Francis (1967) was a word frequency count widely used at the time by psychologists to control for variation in the characteristics of stimuli used in word recognition studies. Nation, of course, is using word frequency for other purposes, principally for determining the difficulty levels of reading texts in English. Gephi cannot distinguish these two uses of the frequency counts, so Nation’s high betweenness score in this data set might not be quite as significant as it appears to be. Cluster IV, at the Western edge of the map, seems to be the 1984 incarnation of the
reading cluster that we identified in 1983. The key influence here is Goodman. Cluster V, in the central part of the map, is made up of only seven sources. This cluster
seems to be mainly concerned with transfer and the development of L2 meanings. This
cluster is the only one of the four smaller clusters that has a direct link with cluster I - Eve
Clark (cluster IV) and Herbert Clark (cluster I) published a number of joint papers in the area of child language acquisition in the early 1980s.
The remaining cluster, Cluster VI, consists of 8 sources - Hartmann, Brown, Fillmore,
Lyons, Crystal, Higgins, Channell and Schouten-van Parreren. These sources are cited at
least twice in the dataset, but the co-citation links between the members of the cluster are
weak. On the other hand, each member of this cluster has a co-citation link to at least two
other clusters, and this suggests that this cluster might represent important sources from
outside the vocabulary research community. Crystal fits this general description, as does
Lyons, whose text book Introduction to General Linguistics (1968) was particularly influential
around this time. However, the general description does not fit the other sources in the
cluster. Hartmann represents a dictionary research strand. Channell and Schouten-van
Parreren are both cited here for their work on guessing behaviour. Schouten-van Parreren
stands out from the other members of this group who are all British or American sources. In
short, it is not easy to establish what holds these sources together as a cluster, but it is
probably something to do with the way L2 meanings are represented.
The majority of the influences in the 1984 map are new sources who did not appear in earlier maps.
The co-citation analysis identifies five clusters of influences in this data, and these are shown in the figure below.
For a more detailed discussion of this map see: Meara, PM
Two steps backwards: A bibliometric analysis of L2 vocabulary research in 1984.
Linguistics Beyond and Within 2 (2016), 139-152.